Intelligent Fault Diagnosis for Telecom Power Systems using Machine Learning Anomaly Detection


Reliable power forms the backbone of telecom power systems. Undetected faults can lead to costly outages and service disruptions. Machine learning anomaly detection now transforms fault diagnosis by enabling rapid, automated identification of irregularities. Operators move away from manual inspections and adopt intelligent, data-driven methods. Early and accurate detection improves operational efficiency, ensures continuous service, and reduces maintenance costs.
Key Takeaways
Machine learning transforms telecom power fault diagnosis by enabling fast, accurate, and automated detection of issues, reducing downtime and costs.
Early fault detection and predictive maintenance help operators fix problems before they cause outages, improving network reliability and customer satisfaction.
Advanced AI models like neural networks and Digital Twins analyze large data sets to spot subtle anomalies and predict failures with high accuracy.
Successful implementation requires quality data collection, careful preprocessing, model training, and real-time monitoring with automated alerts.
Challenges like data quality, scalability, and model interpretability must be addressed to build trustworthy and effective AI-based fault diagnosis systems.
ML and AI in Fault Diagnosis
Traditional vs. Intelligent Methods
Traditional fault diagnosis in telecom relies on manual inspections, rule-based systems, and basic feature models. These approaches often struggle with accuracy, especially when environmental factors such as weather introduce noise and complexity. Technicians must perform multiple rounds of debugging and physical probing, which can extend repair times to days or weeks. Manual methods typically use simple thresholds and alarms, resulting in frequent delays and high operational costs.
Machine learning and AI-driven methods transform this process. Advanced models, including convolutional neural networks (CNNs) and CatBoost algorithms, analyze large volumes of real-time data. These systems automatically extract features, classify faults, and adapt to changing conditions. For example, CNN-based fault detection using thermal imaging and RMS current measurement significantly improves precision and reliability. AI-driven diagnostics achieve fault diagnosis accuracies above 96%, outperforming traditional approaches in robustness and adaptability.
Feature | Manual (Traditional) Diagnostics | AI-driven Diagnostics |
|---|---|---|
Approach | Reactive and manual | Proactive and autonomous |
Data Processing | Basic thresholds and alarms | Advanced AI models analyzing large datasets in real-time |
Efficiency | Slower, frequent delays in issue resolution | Faster and more accurate diagnostics with minimal downtime |
Maintenance | Scheduled, often causing unnecessary downtime | Predictive, minimizing disruptions |
Scalability | Difficult to manage large, complex networks | Easily scalable for growing network demands |
High operational costs due to manual intervention | Reduced costs through automation and efficiency gains |
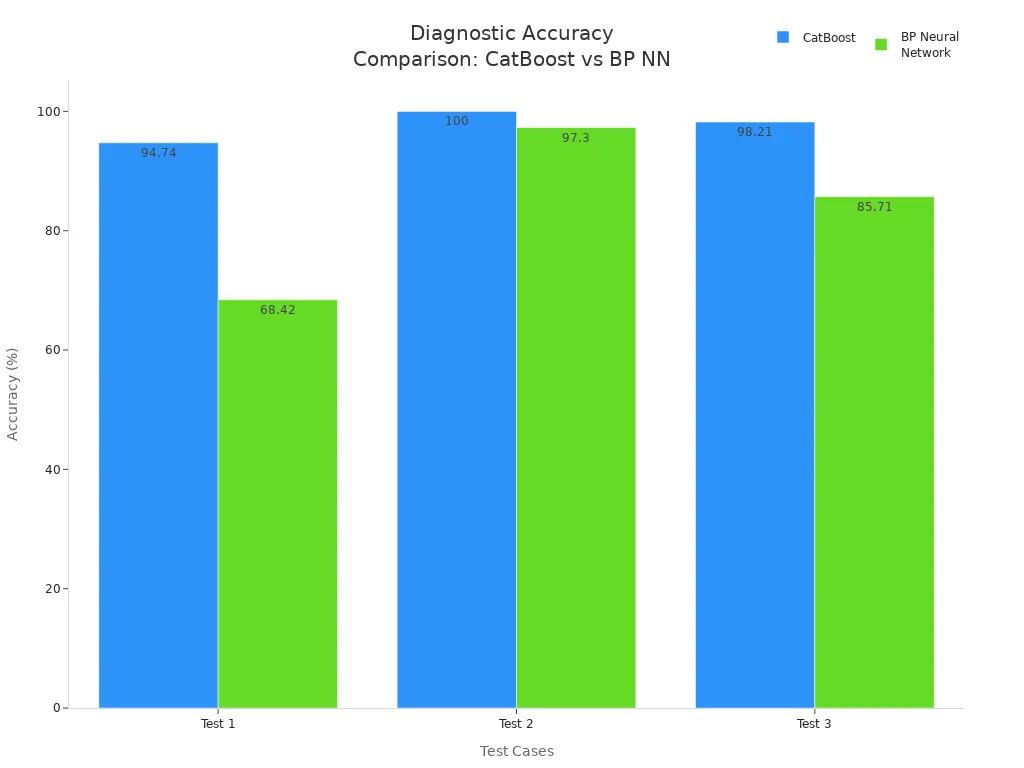
Key Benefits
AI-driven fault diagnosis delivers measurable operational improvements. Companies report up to 80% automation of network monitoring tasks by 2025, with productivity increasing by 30% due to automated fault detection and correction. Fault response times decrease by 25%, leading to faster issue resolution and improved network reliability. These systems also reduce mean time to detect and resolve faults, optimize maintenance schedules, and minimize downtime.
Operational Benefit | Measurable Improvement |
|---|---|
Network monitoring automation | AI agents expected to handle 80% of monitoring tasks by 2025 |
Productivity boost | Around 30% increase due to automation of fault detection and correction |
Fault response time | Reduced by 25% for faster issue resolution |
Network reliability | Significant reduction in outages, improving trust and service quality |
Cost savings | Long-term savings from fewer disruptions and repairs |
Tip: AI-powered anomaly detection not only improves diagnostic accuracy but also lowers maintenance costs by enabling timely interventions and proactive network management.
Faults in Telecom Power Systems

Main Components
Telecom power systems rely on several critical components to maintain continuous operation. The power supply stands out as the most vulnerable part. High thermal and electrical stresses from fluctuating input power and rapid switching often cause failures. Backup batteries play a vital role in preventing total system dysfunction when the main power supply fails. Engineers design fault-tolerant systems with features such as uninterruptible power supplies (UPS) and battery banks to ensure uninterrupted service.
Other components frequently experience faults due to environmental and operational stresses.
Capacitors, especially electrolytic types, often fail from heat, overstress, or aging. These failures can result in leakage, swelling, or short circuits, sometimes causing corrosion.
Power switching devices like MOSFETs may fail because of inadequate heat sinking, overvoltage, or overcurrent.
Power diodes, particularly Schottky diodes, are sensitive to voltage spikes and thermal issues.
Control ICs can malfunction if applied incorrectly or if their operation becomes unstable, which may damage downstream components.
Environmental factors, including moisture ingress and power surges, contribute significantly to component failures.
DC surge protection remains essential for safeguarding infrastructure. It prevents damage from power spikes caused by lightning or grid issues, protects battery life, and ensures continuous network operation.
Common Fault Types
Faults in telecom power systems arise from various causes, each with distinct impacts. The table below summarizes frequent fault types, their causes, and typical consequences.
Fault Type | Causes | Impact/Notes |
|---|---|---|
Transient Instabilities | Faults, topological changes, lightning, load switching, capacitor bank switching | Voltage fluctuations, auxiliary supply tripping, long resynchronization times |
Voltage Instabilities | Heavy loading, insufficient reactive support, mis-coordinated tap-changing transformers | Low voltage profiles, risk of system-wide blackouts |
Overloads | Overloading of system elements, heavily loaded generators or motors | Cascading overloads, potential complete blackout |
Power Outages | Equipment malfunctions, human error, storms, high population load | Service disruption, loss of connectivity |
Power Surges | Lightning, load disconnection, line switching, heavy equipment shutoff | Damage to sensitive electronics, reduced battery life |
Power Sags | Faults in transmission or distribution networks | Temporary voltage drops, possible equipment malfunction |
Natural Causes | Storms, lightning, rain, snow, fierce winds, moisture exposure | Physical damage, increased risk of outages |
Animals | Birds or other animals contacting power lines | Unexpected outages, equipment damage |
Note: Transients, such as sudden deviations in voltage or current, often result from lightning, electrostatic discharge, or faulty wiring. These events can cause short-term disruptions but may lead to long-term equipment damage if not addressed promptly.
Early Detection Importance
Operational Impact
Early detection of faults plays a critical role in maintaining high system uptime. Continuous monitoring systems allow operators to identify issues in underground cable segments before they escalate. For example, a real-world deployment used advanced processing to locate faults accurately, which helped prevent outages and reduced maintenance costs. Operators who monitor partial discharges in real time receive early warnings about cable health. This approach enables them to act before minor issues become major failures.
Real-time surveillance provides a clear picture of equipment status. When operators detect faults early, they can schedule repairs before service interruptions occur. This proactive strategy not only prevents future damage but also reduces economic losses. Companies that adopt early detection methods report improved operational efficiency. They experience fewer outages, lower maintenance expenses, and better customer satisfaction. By minimizing downtime, operators protect revenue streams and enhance their brand reputation.
Empirical studies show that early fault detection in non-redundant network segments directly reduces service interruptions. Advanced detection systems can identify and isolate faults up to 2.33 hours faster than traditional alarms. This speed allows for quicker repairs and less disruption for customers. Integrating customer reports with automated detection further improves fault management and reduces false alarms.
Preventive Maintenance
Predictive maintenance, powered by machine learning anomaly detection, transforms how operators manage network health. These models analyze real-time and historical data to spot subtle changes in equipment behavior. When the system detects an anomaly, it triggers automated alerts and troubleshooting steps.
Machine learning models monitor sensor data and equipment logs for early signs of failure.
Operators receive alerts that allow them to schedule maintenance before equipment breaks down.
Automated systems help address issues promptly, reducing downtime and unplanned outages.
Integration with IoT sensors and edge computing improves prediction accuracy and response times.
Predictive maintenance reduces downtime by up to 50% and extends equipment life by as much as 40%. Operators benefit from optimized maintenance schedules, cost savings, and improved network reliability. Customers enjoy more consistent service with fewer disruptions, which strengthens trust and loyalty.
Anomaly Detection in Telecom Power Systems
Machine Learning Approaches
Machine learning algorithms have become essential for detecting anomalies in telecom power systems. Classification And Regression Tree (CART) and Multi-Layer Perceptron (MLP) stand out as highly effective options. CART offers clear interpretability, allowing domain experts to understand and contextualize detected anomalies. This transparency helps engineers make informed decisions quickly. MLP provides higher accuracy and finer resolution, identifying subtle irregularities that traditional methods often miss. However, MLP models can be less interpretable, which sometimes complicates troubleshooting.
A semi-supervised framework that combines CART and MLP leverages the strengths of both. CART delivers actionable insights, while MLP enhances detection precision. This approach improves both the accuracy and interpretability of anomaly detection. Engineers can address faults faster and with greater confidence.
Note: Machine learning models process vast amounts of electricity consumption data, enabling early identification of abnormal patterns and supporting proactive maintenance strategies.
Deep Learning Models
Deep learning models have revolutionized anomaly detection in telecom power systems. Weighted Convolutional Neural Networks (WCNN) and Digital Twin concepts provide advanced feature extraction and predictive capabilities. WCNN models analyze complex time series data, identifying abnormal patterns with high accuracy. These models excel at processing large datasets and extracting meaningful features, which traditional methods often overlook.
Transformer-GAN models combine the self-attention mechanism of Transformers with the generative power of GANs. This combination captures long-term dependencies in time series data and learns the distribution of normal operating conditions. As a result, these models detect novel or unseen anomalies more effectively. Adaptive learning mechanisms allow these models to adjust parameters dynamically, improving performance as data patterns evolve.
Model Type | Key Features | Advantages Over Traditional Methods |
|---|---|---|
WCNN | Advanced feature extraction, time series analysis | High accuracy, robust to dynamic changes |
Transformer-GAN | Self-attention, generative learning | Detects novel anomalies, adapts to new patterns |
Digital Twin | Virtual system replication | Predictive analytics, real-time monitoring |
Deep learning approaches offer superior accuracy, adaptability, and robustness. They overcome limitations such as dependence on labeled data and poor detection of new anomaly patterns. Telecom power systems benefit from these models through improved fault detection and reduced downtime.
Digital Twin and AI Innovations
Digital Twin technology creates a virtual replica of physical telecom power systems. This innovation enables real-time monitoring, predictive analytics, and scenario simulation. Engineers use Digital Twins to test fault scenarios, optimize maintenance schedules, and predict system behavior under different conditions. AI-driven Digital Twins integrate sensor data, operational logs, and historical records, providing a comprehensive view of system health.
Data alignment techniques play a critical role in maximizing the benefits of AI-driven fault diagnosis. These techniques consolidate diverse network, operational, and customer data into a unified platform. The unified environment supports seamless cross-domain analytics, allowing AI models to generate actionable insights and optimize network performance. Real-time, consistent data inputs improve the accuracy and effectiveness of anomaly detection.
Data alignment creates a single source of truth for all system data.
Cross-domain analytics enable holistic fault prediction and network optimization.
Real-time data inputs reduce false positives and expedite fault resolution.
Self-healing capabilities autonomously reroute traffic and replace failing components, improving SLA compliance by up to 30%.
Predictive maintenance powered by aligned data reduces network downtime by up to 35%.
Operational automation lowers Mean Time to Repair (MTTR) by 50%, reducing manual intervention and operational costs.
Tip: Data alignment and Digital Twin innovations form the foundation of next-generation fault diagnosis, delivering superior resilience and operational efficiency for telecom power systems.
Implementation Workflow

Data Collection
Effective fault diagnosis in telecom power systems begins with robust data collection. Operators gather diverse data types, including topological data, temporal operational records, and large-scale sensor measurements. Real-time alarm monitoring, device logs, and network testing results provide a comprehensive view of system health. Distributed computing at the edge and in the cloud ensures timely data ingestion and reduces latency. Tools such as Prometheus and Kafka help automate the collection and streaming of metrics, logs, and traces from power system devices.
Note: Data credibility and validity remain essential for high diagnostic performance. Reliable data supports accurate anomaly detection and reduces false positives.
Preprocessing and Features
After collection, data undergoes preprocessing to ensure quality and consistency. This step includes cleaning, normalization, and handling missing values. Feature engineering follows, where relevant attributes are extracted to capture trends and unusual behaviors. Feature selection reduces dimensionality by removing redundant information, which improves model accuracy and computational efficiency. Advanced techniques, such as graph convolutional networks, help capture complex relationships within the data, enhancing diagnostic performance.
Preprocessing ensures data integrity.
Feature selection and extraction boost model generalization and reliability.
Model Training
Model training forms the core of the workflow. Engineers select suitable algorithms, such as Random Forest, Support Vector Machines, or Artificial Neural Networks, based on the problem and data characteristics. Supervised learning uses labeled fault data, while unsupervised learning models normal system behavior to detect unknown faults. Iterative frameworks guide systematic development, and model evaluation uses metrics like R-squared and Mean Absolute Error. Continuous retraining with new data adapts the model to evolving fault patterns, ensuring sustained performance.
Real-Time Monitoring
Trained models deploy into live environments to monitor data streams in real time. The system detects anomalies instantly and triggers automated alerts or remediation workflows. Unified dashboards, built with tools like Grafana and Kibana, visualize system health and highlight anomalies for quick intervention. Automated responses reduce manual effort and speed up fault resolution. Continuous feedback loops support model improvement and maintain high reliability in telecom power systems.
Real-World Applications
Deployment Examples
Telecom operators have embraced machine learning-based fault diagnosis to enhance reliability and efficiency. AT&T deployed AI-driven monitoring across its network, automating fault detection and reducing manual inspection time. Verizon integrated neural network models into its infrastructure, enabling real-time alerts for abnormal power consumption and equipment failures. BT implemented predictive maintenance using Random Forest algorithms, which forecasted equipment issues before they caused outages.
These deployments demonstrate practical benefits. Automated systems monitor thousands of devices simultaneously, identifying faults that manual methods often miss. Operators receive timely notifications, allowing them to address problems before they escalate. Proactive maintenance schedules minimize downtime and extend equipment lifespan. Companies report significant reductions in service interruptions and maintenance costs after adopting intelligent fault management.
Operators who leverage AI and machine learning in telecom power systems achieve faster fault resolution and improved network stability.
Performance Metrics
Performance improvements after deploying machine learning solutions are measurable and impactful. Automated monitoring reduces manual effort and optimizes spare parts inventory. Predictive models increase fault detection accuracy and enable proactive maintenance. Real-time monitoring allows immediate corrective actions, improving system responsiveness.
Performance Improvement | Description |
|---|---|
Predictive Maintenance | Forecasts equipment failures, reducing downtime and maintenance costs |
Fault Detection & Diagnostics | Enhances accuracy and speed in identifying faults |
Real-Time Monitoring & Control | Enables immediate corrective actions for better system responsiveness |
Network Optimization | Balances loads and minimizes energy losses, increasing efficiency |
Dynamic Power Management | Adjusts power consumption based on demand, saving energy |
Equipment Reliability & Lifespan | Extends operational life and reliability of telecom power equipment |
Smart Grid Integration | Facilitates stable power supply and demand response |
Operators report that mean time to detect and resolve faults drops significantly with AI-powered systems. Early identification and resolution of faults enhance overall network performance. Telecom power systems benefit from increased uptime, reduced costs, and improved customer satisfaction.
Challenges and Solutions
Data Quality
High-quality data forms the backbone of reliable machine learning models. Accurate labels, consistency, and completeness ensure that models learn correct patterns. Poor data quality, such as missing values or label errors, destabilizes benchmarks and reduces accuracy. Noise and errors in training data can cause negative effects that spread through the entire system. Deep learning models, in particular, require large, well-labeled datasets. Noisy or incomplete data limits their ability to improve, even with more samples. Improving data quality often yields better results than simply increasing dataset size. Teams must focus on data cleaning, validation, and robust labeling practices to achieve dependable fault diagnosis.
Scalability
Modern networks generate massive volumes of data every second. Machine learning systems must scale to handle this influx without sacrificing speed or accuracy. Operators face challenges in processing, storing, and analyzing such large datasets. Distributed computing and cloud-based solutions help address these issues. Automated data pipelines and real-time analytics platforms enable seamless scaling. Engineers must design models and infrastructure that adapt to growing network demands. Scalability ensures that fault detection remains effective as networks expand.
Interpretability
Engineers and operators need to understand how AI models make decisions. Interpretability remains a key challenge, especially with complex deep learning models. Black-box systems can create trust issues and slow down troubleshooting. Clear explanations of model outputs help experts validate flagged anomalies and take appropriate action. Combining interpretable models, such as decision trees, with high-accuracy neural networks can balance transparency and performance. Human expertise plays a vital role in defining anomalies, interpreting results, and providing feedback to improve models.
Note: Interpretability not only builds trust but also supports compliance with industry regulations and ethical standards.
Emerging Trends
The field continues to evolve with new solutions for persistent challenges:
Privacy protection gains importance. Data anonymization and encryption safeguard sensitive information.
Compliance with regulations like GDPR and CCPA becomes standard practice.
Bias mitigation and fairness auditing address concerns about unfair outcomes in AI decisions.
Adversarial training strengthens models against attacks that attempt to evade detection.
Human-in-the-loop systems combine AI efficiency with expert oversight, improving accuracy and reliability.
These trends shape the future of intelligent fault diagnosis, making systems more secure, fair, and resilient.
Best Practices
Implementation Steps
Successful deployment of intelligent fault diagnosis begins with a structured approach. Teams should start by defining clear objectives for the monitoring system. They need to identify critical assets and prioritize components that impact network reliability. Data collection forms the foundation. Engineers must ensure sensors and logging devices capture accurate, high-frequency data from all relevant sources.
Data preprocessing follows. Teams clean and normalize the data, removing noise and filling gaps. Feature engineering helps extract meaningful patterns that improve model performance. Model selection comes next. Engineers evaluate different algorithms, such as decision trees or neural networks, based on the specific use case and available data. Training and validation require careful attention. Teams should split data into training and testing sets, using cross-validation to avoid overfitting.
Deployment involves integrating the trained model into existing monitoring platforms. Real-time dashboards and automated alerting systems help operators respond quickly to detected anomalies. Continuous feedback loops allow teams to refine models as new data becomes available.
Tip: Document each step and maintain version control for data, code, and models. This practice ensures traceability and supports future audits.
Long-Term Success
Long-term success depends on ongoing evaluation and adaptation. Teams should monitor model performance using key metrics, such as detection accuracy and false positive rates. Regular retraining with fresh data keeps the system responsive to evolving fault patterns. Collaboration between data scientists and field engineers strengthens the feedback process.
Operators benefit from periodic reviews of system objectives and performance. They should update maintenance schedules and response protocols based on insights from anomaly detection. Investing in staff training ensures that operators understand both the technology and its practical applications.
A culture of continuous improvement drives operational excellence. Organizations that embrace innovation and adapt to new challenges maintain high reliability and customer satisfaction.
Machine learning anomaly detection has transformed operational excellence by increasing detection accuracy, reducing false alarms, and enabling real-time monitoring. Recent advances, such as enhanced DeBERTa-v3 models, deliver up to 95% precision and recall, as shown below.
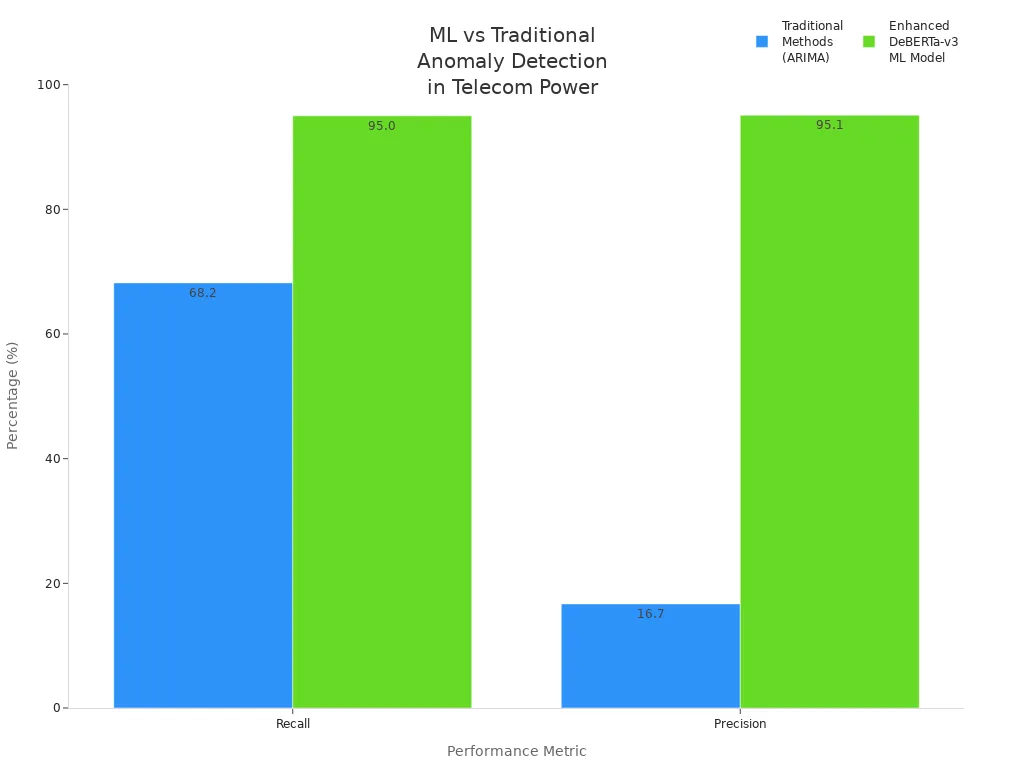
To achieve lasting results, organizations should apply best practices and explore new AI-driven strategies. Ongoing innovation in automated fault management, predictive maintenance, and real-time optimization will drive future reliability. Continuous improvement remains essential for operational success.
FAQ
What is anomaly detection in telecom power systems?
Anomaly detection identifies unusual patterns or behaviors in power system data. Engineers use machine learning models to spot faults early. These models analyze sensor readings and operational logs to improve reliability and reduce downtime.
How does machine learning improve fault diagnosis accuracy?
Machine learning models learn from historical data. They recognize complex fault patterns that manual methods often miss. Operators achieve higher diagnostic accuracy and faster response times by deploying these models in real-time monitoring systems.
Which data sources support intelligent fault diagnosis?
Operators collect data from sensors, device logs, network alarms, and operational records. Real-time and historical data provide a comprehensive view of system health. Data alignment techniques help unify these sources for effective analysis.
Tip: Consistent data collection ensures reliable fault detection and supports predictive maintenance.
What challenges do telecom operators face when implementing AI-based fault diagnosis?
Operators encounter issues with data quality, scalability, and model interpretability. They address these challenges by cleaning data, using distributed computing, and combining interpretable models with deep learning for balanced performance.
Can AI-based systems reduce maintenance costs?
AI-based systems automate fault detection and enable predictive maintenance. Companies report fewer outages and lower repair expenses. Automated monitoring helps optimize maintenance schedules and extends equipment lifespan.
See Also
Methods To Calculate Power Systems And Batteries For Telecom
Introductory Guide To Telecom Power Supply Systems Explained
Key Features You Should Understand About Telecom Power Supplies
Steps To Guarantee Consistent Power Supply Within Telecom Cabinets
Using Solar Energy Storage Systems For Telecom Cabinet Power
CALL US DIRECTLY
86-13752765943
3A-8, SHUIWAN 1979 SQUARE (PHASE II), NO.111, TAIZI ROAD,SHUIWAN COMMUNITY, ZHAOSHANG STREET, NANSHAN DISTRICT, SHENZHEN, GUANGDONG, CHINA